WindowsとLinuxのパッチ管理の違い
「同じパッチ管理」という言葉でくくると見えなくなる、OS別の構造的な違いを整理します。
パッチの提供形態の違い
Windows : マイクロソフトが月例(第2火曜)に累積更新プログラムをまとめて提供。基本「一律これを当てればよい」設計Linux : ディストリビューションごとに(RHEL / Ubuntu / SUSE など)、パッケージごとに(OpenSSL / glibc / Kernel など)、個別にパッチが提供される
配信・適用の仕組みの違い
Windows : マイクロソフトが提供する配信インフラ(WSUS / Windows Update for Business(WUfB))が事実上の標準。配信タイミングや適用対象の制御はその枠組みの中で行うLinux : yum / apt / zypper などディストリビューション付属のパッケージ管理システムが標準。配信インフラは組織ごとに自社リポジトリミラーを構築することが多い
適用対象とライフサイクルの違い
Windows : クライアント端末(数千〜数万台)が中心。ユーザーが使う端末でいかに業務影響なく当てるかが焦点Linux : サーバー(数十〜数百台)が中心。24 時間稼働の業務基盤が多く、再起動・サービス停止のタイミング調整が焦点
パッチ管理のよくある課題
同じパッチ管理でも、OS が違えば課題も異なります。課題を整理することで、経営層と現場の温度差の本質が見えてきます。
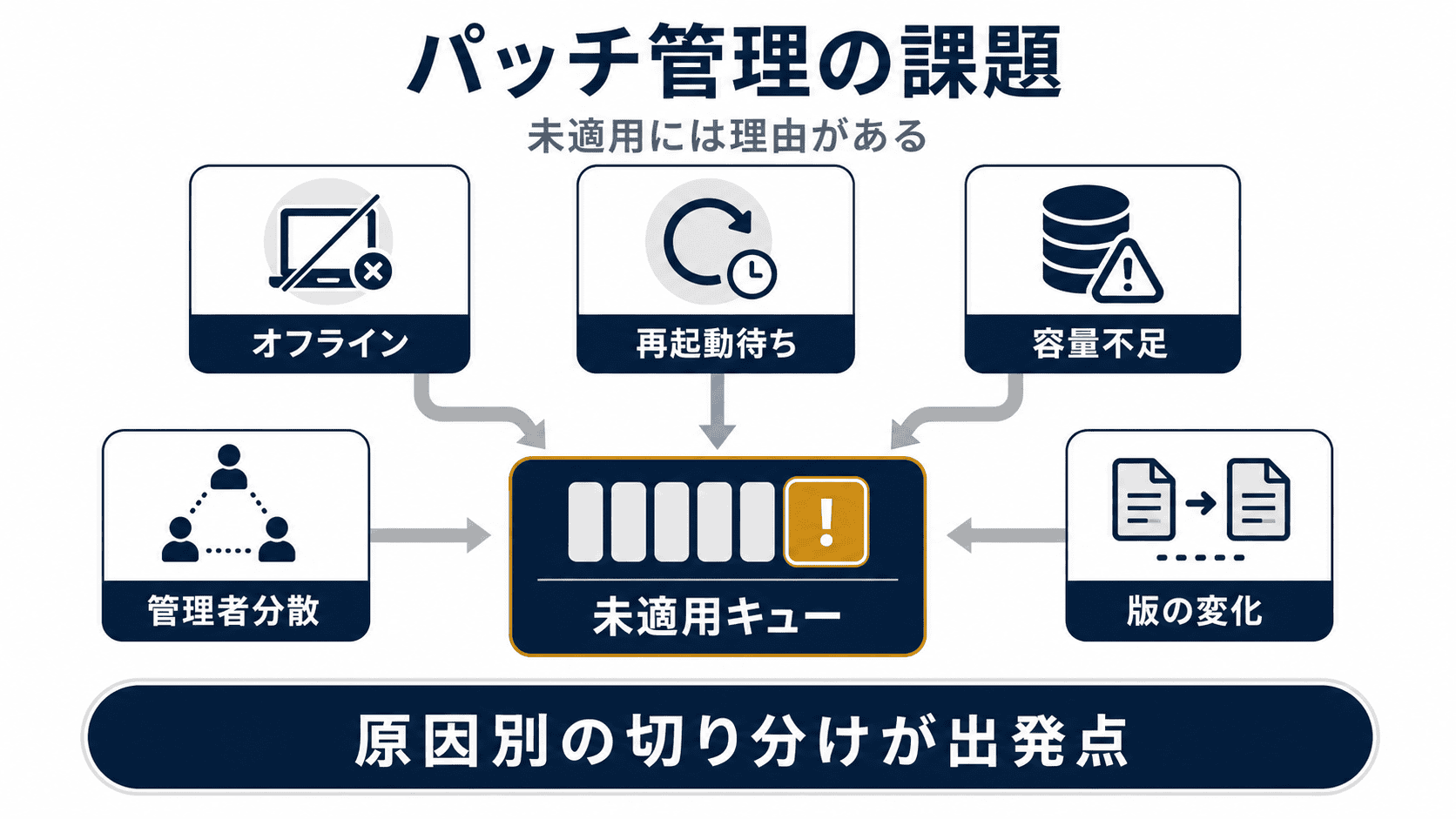
Windows と Linux に共通する、パッチ管理現場のよくある課題 Windowsでよくある課題
WSUSは「端末が取りに来ないと適用されない」仕組み 業務アプリが動かなくなるからとアップデートを止めている端末 ずっと再起動していない端末 WSUSのレポートが見づらく、反映も遅い WSUSサーバー自体の運用負荷
並べてみるとシンプルな話に見えますが、現場で一つひとつ対処していくとなると思った以上に手間がかかります。
Linuxでよくある課題
管理者がバラバラ ディストリビューションがバラバラ サービスを止めにくい 適用前の検証が必須 検証環境と本番でリポジトリの中身が変わる パッチ適用を運用に組み込んでいないサーバー
結果として「Linuxは後回し」「触らないが正解」というムードが組織に広がりがちです。
Taniumで何が変わるのか
Tanium を入れると、パッチ管理まわりで次の 3 つが変わります。
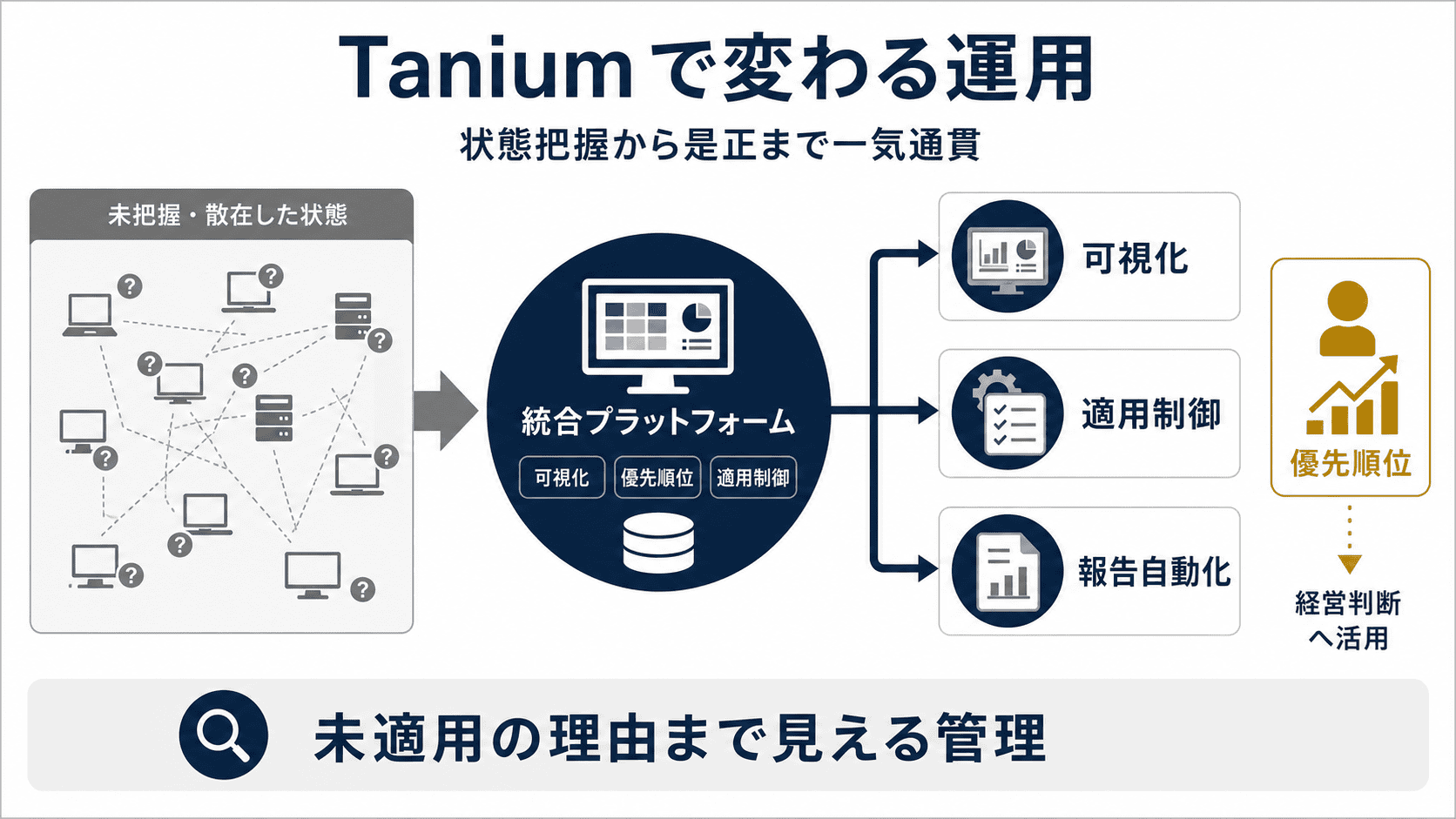
Tanium 導入でパッチ管理がどう変わるかの全体像 適用状態が把握できる
どの端末に何が当たっていて、何が未適用なのかがわかります。さらに「再起動していない」「アップデートを止めている」「オフライン」「ストレージ不足」「サポート切れOS」など、なぜ適用できていないのか まで原因を調査できるので、是正の打ち手まで具体的に決められます。
パッチ適用が効率的になる
「強制的に当てる」「再起動のタイミングをコントロールする」「ユーザー自身に好きなタイミングで当ててもらう」など、場面に合った当て方を使い分けられます。脆弱性スキャンの結果を起点に「優先順位の高いところから当てる」という動き方にも切り替えやすくなります。
運用が楽になる
月例パッチの条件指定での自動配信、配信リングでの段階展開、メンテナンスウィンドウ制御。これまで毎月手で回していた作業の多くを定型化できます。経営層 への月次報告も、パッチ適用率 や 平均適用日数 といった指標で語れるようになります。
このあと、Windows と Linux それぞれで、現場でありがちなシナリオに沿って具体的な戦略を紹介します。
Windowsのパッチ管理の戦略
Tanium を導入したからといって、必ずしも WSUS / Windows Update for Business(WUfB)といった既存の仕組みを廃止する必要はありません。Windowsのパッチ管理の戦略は、大きく次の 3 パターンに整理できます。
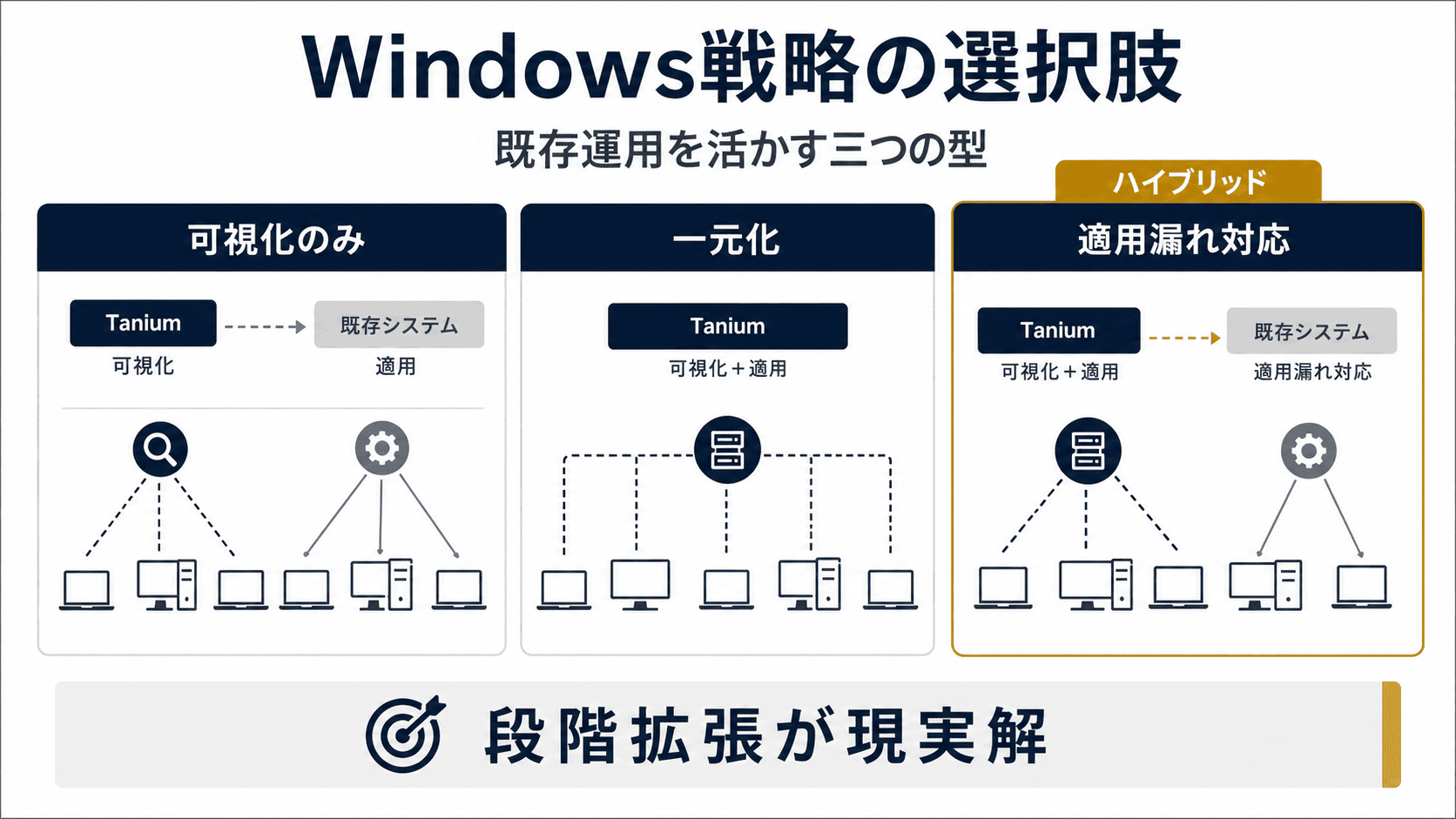
Tanium と既存の Microsoft 配信インフラを組み合わせる 3 パターンの戦略 パターン1:可視化 Tanium / 適用 Microsoft(WSUS / WUfB)
現在の WSUS や WUfB の運用に大きなトラブルがなく、まずは現状を補完するところから始めたい組織向けです。毎月のパッチ配信は WSUS / WUfB で継続しつつ、Tanium を「監査役」として併用します。レポートだけでは把握しきれない「本当に適用されたか」「適用に失敗し続けている端末はどこか」を、Tanium の高速な可視化機能で補完し、管理の死角をなくします。可視化だけならすぐに始められるので、最初の一歩としてもっとも入りやすいパターンです。
パターン2:可視化 Tanium / 適用 Tanium
既存のパッチ管理システム(WSUS / WUfB など)を廃止し、Tanium でパッチ管理を一元化するパターンです。最大のメリットは、Tanium 独自の「リニアチェーン(Linear Chain)」技術を活用できる点。端末同士がファイルを共有し合うことで、WAN 回線やインターネット帯域への負荷を最小限に抑えながら、大規模環境へパッチを配信・適用できます。既存のパッチ管理インフラの運用負荷からも解放されるため、インフラコストの削減と管理ツールの統合を同時に実現したい場合に向いています。
パターン3:ハイブリッド(可視化 Tanium / 適用 Microsoft + Tanium)
平時は WSUS / WUfB でパッチを適用しつつ、適用漏れが発生した端末に対してだけ Tanium で配信するパターンです。「どうしても当たらない端末」に Tanium の配信力を使う現実的なアプローチで、多くの組織で採用されています。
ポイント :実案件で多く採用されているのは、パターン 1 とパターン 3 です。まずはパターン 1 で「本当に当たっているか」を可視化し、適用漏れ端末に Tanium 配信を組み合わせるパターン 3 へ段階的に拡張する流れが現実的です。
Windowsのケーススタディ
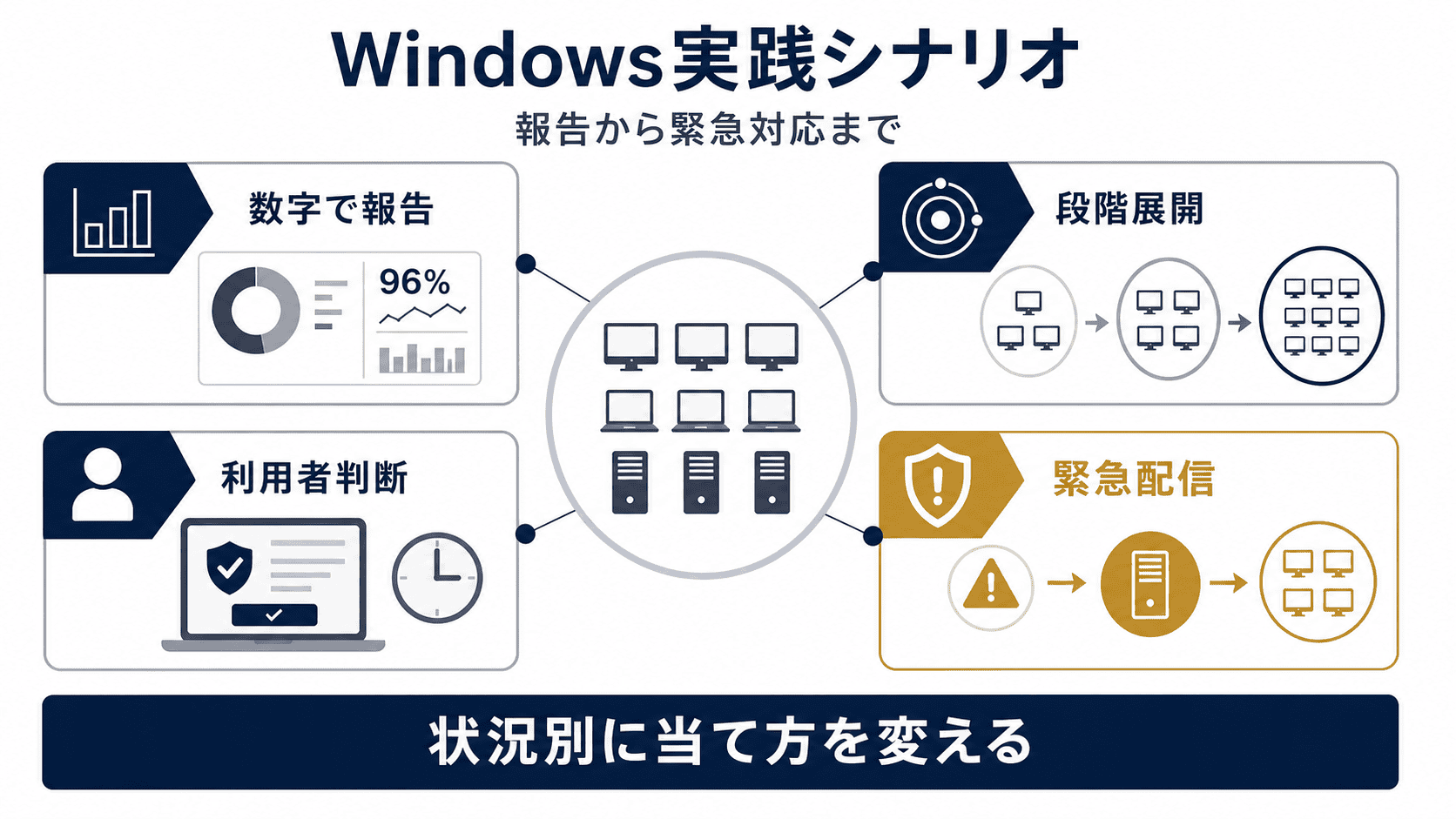
Windows パッチ管理の 4 つのケーススタディ ケーススタディ1:経営層に適用状況を数字で答えられるようにしたい
状況の説明
経営層にパッチ適用状況を聞かれても、WSUS のレポートでは即座に数字で答えにくい。各部門へのヒアリングで集計するのも時間がかかる。
Taniumを使った対策
適用状況の把握 :個別パッチ単位での確認 :未適用原因の切り分け :報告とフォローの自動化 :
ポイント :月例パッチや、一定以上の基準を満たすパッチは、あらかじめレポートを作成しておけば、経営層の急な確認にも対応できます。
ケーススタディ2:月例パッチを段階的に展開し、適用完了率を底上げしたい
状況の説明
第 2 火曜の月例パッチを、業務影響を抑えつつできるだけ早く適用したい。WSUS は端末が自分から取りに来ないと適用されない仕組みのため、適用漏れが構造的に発生しがち。適用状況の把握にも時間がかかり、個別対応でのフォローに頼らざるをえない。
Taniumを使った対策
配信対象の絞り込み :段階的な展開 :ユーザー判断と強制適用の併用 :再起動のコントロール :時間帯の制限 :
ポイント :月例パッチなど毎月必ず適用するパッチは配信を自動化してしまうのが効果的かつ効率的です。未適用端末のフォロー手順もあらかじめ決めておきましょう。
ケーススタディ3:特定用途の端末は「勝手に当てられたら困る」、ユーザー判断で適用させたい
状況の説明
開発端末、計測端末、検証用PC、役員端末など、業務都合で「今は再起動・適用してほしくない」端末は必ず存在します。製造サイクル間でしかパッチできない製造端末や、手術間でしかパッチできない手術室端末まで含めると、業界を問わず広く見られる課題です。
Taniumを使った対策
対象端末のグループ化 :ユーザー任意での適用 :再起動通知のコントロール :デッドライン超過分のフォロー :
ポイント :ユーザー判断にする対象端末の定義、デッドラインを過ぎた場合の強制配信切替えルール、例外申請の承認フローを定めておきましょう。加えて、パッチ適用をやるべきこととして運用に組み込むことが大切です。
ケーススタディ4:緊急のゼロデイ・Out-of-Bandパッチを今すぐ当てたい
状況の説明
話題のゼロデイ脆弱性が公開され、経営層から「うちは大丈夫か。いつまでに当たるのか」と即問われる。この場面で即答できるかどうかは、平時の準備で決まります。
Taniumを使った対策
影響範囲の即時把握 :パッチ信頼性の確認 :緊急配信ルートの確保 :時間帯制限のオーバーライド :再起動の確実な完了 :
ポイント :緊急パッチの基準と対応手順(誰が判断し、いつまでに、どうやって当てるか)を平時に整理し、経営層も含めて合意しておきましょう。
Linuxのパッチ管理の戦略
Linuxでよくある課題で挙げたように、未適用パッチを片っ端から潰すという単純な話では片付けられません。
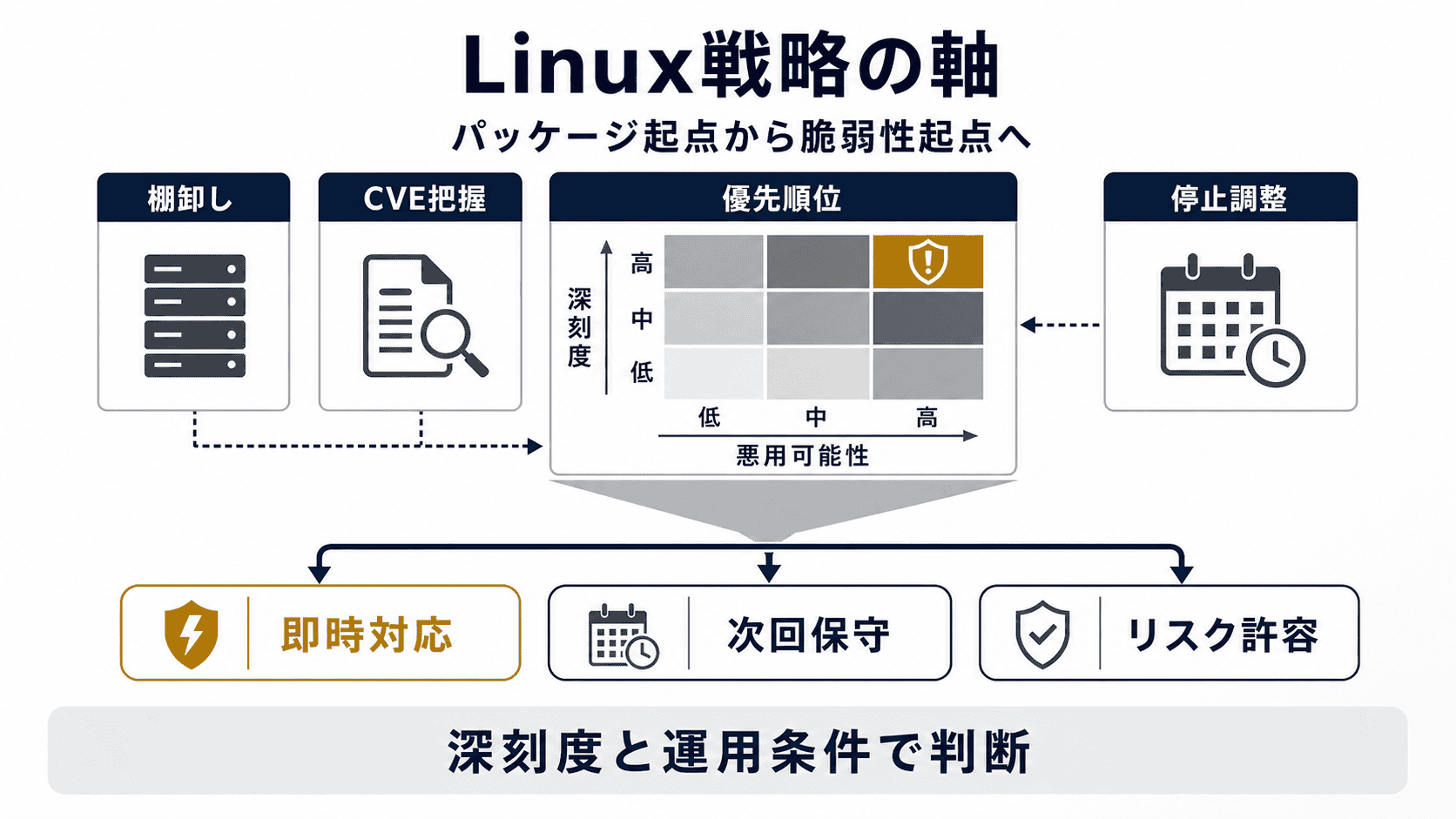
そこで重要になってくるのが、パッケージ(パッチ)起点ではなく、脆弱性起点で考える というアプローチです。
脆弱性起点で考える Linux パッチ管理の戦略
管理者・意思決定者の明確化 :脆弱性起点での優先順位付け :対応基準の明文化 :運用整備 :
Linuxのケーススタディ
Linux パッチ管理の 2 つのケーススタディ ケーススタディ1:「未適用パッチが数百件、どこから手をつければ…」を脱したい
状況の説明
Linux サーバーをスキャンしたら未適用パッチが数百件検出され、優先順位もつけられず手が止まっている。「Linux は後回し」が状態化している。
Taniumを使った対策
OSの棚卸し :脆弱性起点での可視化 :指標による優先順位付け :脆弱性→適切な対処 :
ポイント :脆弱性が検出されてから対応方針を決めるのではなく、あらかじめ各指標を参考に対応方針を決めておくことが迅速な対処につながり、攻撃によるリスクを下げることにつながります。
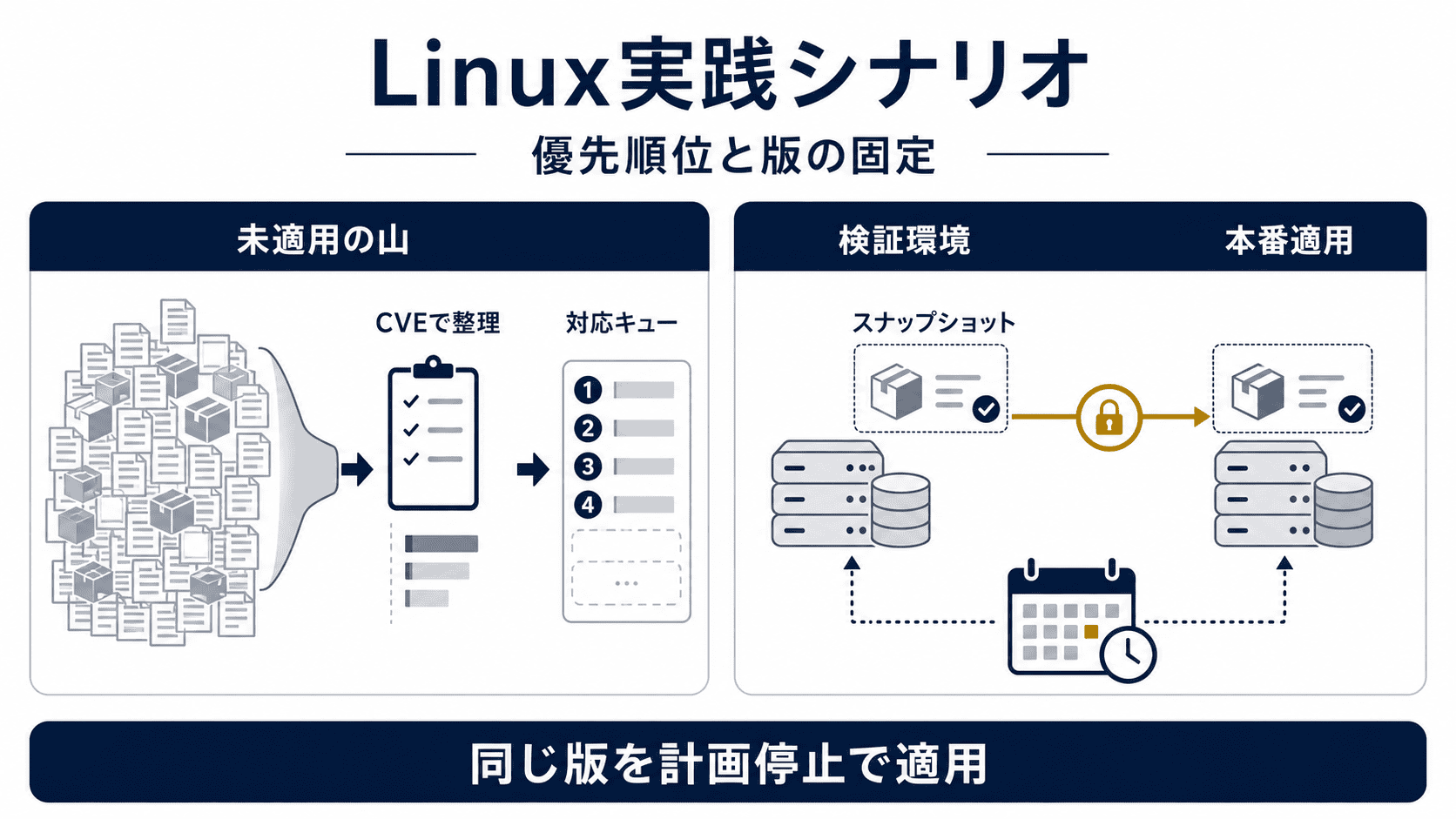
ケーススタディ2:検証で問題なくても本番で「違うバージョンが入った」事故を防ぎたい
状況の説明
Linux のリポジトリは日々更新されるため、あるバージョンで検証していざ本番に適用しようとすると、検証時とは異なるバージョンが入ってしまうリスクがあります。
Taniumを使った対策
検証前のリポジトリスナップショット取得 :配信対象サーバーへのターゲティング :計画停止に合わせた実行 :
ポイント :月に 1 回メンテナンスウィンドウを確保しておくなど、パッチ適用を想定した運用設計が重要です。